Game Changing Tools for Evidence Synthesis: Generative AI, Data and Policy Design

Geoff Mulgan and Sarah O’Meara
Evidence synthesis aims to make sense of huge bodies of evidence from around the world and make it available for busy decision-makers. Google search was in some respects a game changer in that you could quickly find out what was happening in a field – but it turned out to be much less useful for judging which evidence was relevant, reliable or high quality. Now large language models (LLM) and generative AI are offering an alternative to Google and again appear to have the potential to dramatically improve evidence synthesis, in an instant bringing together large bodies of knowledge and making it available to policy-makers, members of parliament or indeed the public.
But again there’s a gap between the promise and the results. ChatGPT is wonderful for producing a rough first draft: but its inputs are often out of date, it can’t distinguish good from bad evidence and its outputs are sometimes made up. So nearly a year after the arrival of ChatGPT we have been investigating how generative AI can be used most effectively, and, linked to that, how new methods can embed evidence into the daily work of governments and provide ways to see if the best available evidence is being used.
We think that these will be game-changers: transforming the everyday life of policy-makers, and making it much easier to mobilise, and assess evidence – especially if human and machine intelligence are combined rather than being seen as alternatives. But they need to be used with care and judgement rather than being panaceas. [Watch IPPO’s recent discussion here].
Generative AI for Evidence Synthesis
ChatGPT is the starting point for considering how we prompt LLMs to more rapidly synthesise research. IPPO’s partner, the EPPI Centre, a highly regarded evidence synthesis organisation, has been evaluating the options, and working out to engineer their tools to lead in a rapidly changing field, without losing the hallmarks of quality that have been built up over decades of work.
With the increased availability of open access research and increased computing power, it’s possible to leverage knowledge much more quickly. But extracting useful insights from the entirety of human knowledge is not so simple. EPPI argues for asking two basic questions of any evidence synthesis tool.

Image from an IPPO presentation delivered by James Thomas, EPPI Centre
Through this lens, ChatGPT clearly fails on both counts, offering incomplete and unreliable results. Other tools such as Connected Papers, Scite, Elicit and EPPI Reviewer do better. As an example we tested all of these on a typical evidence question: Are mindfulness interventions effective for smoking cessation among people who smoke?
Connected Papers takes an open access data set of scientific knowledge and enables researchers to interact with it in quite a visual way. You start with a seed paper and then it shows you both the citation relationships and also the conceptual relationships. One drawback is that it rather overemphasises citation levels as being a useful metric. It doesn’t allow you to draw on the sum of knowledge, but it does enable you to distinguish between reliable and unreliable research.
Answer: No generated answer.
Scite is a more sophisticated tool than CP. It draws on a database of scientific papers, and also uses a LLM model so can answer questions in a similar way to ChatGPT It doesn’t allow you to draw on the sum of knowledge, but it does enable you to distinguish between reliable and unreliable research by reading all the papers included in its overview. However, it doesn’t distinguish between different types of research, such as reviews of research, and individual studies.
Answer: There is evidence to suggest that mindfulness-based interventions can be beneficial for reducing smoking behaviour and promoting quit attempts.
Elicit is one of the most advanced tools available. Again, there’s a question mark whether it allows you to draw on the sum of knowledge (although it’s probably further along the right lines than other tools), but it does enable you to distinguish between reliable and unreliable research to a certain extent, in that you can read the papers yourself to their value.
Answer: The research of mindfulness-based interventions for smoking cessation is promising but mixed.
This does enable you to draw on the sum of knowledge and enable you to distinguish between reliable and unreliable research.
Answer: There is currently no clear evidence that mindfulness based treatments help people to stop smoking or improve their mental health and wellbeing, however our confidence in the evidence is low, and further evidence is likely to change our conclusions.
These examples confirm that the prompt given to an AI platform is key to finding the results you need. As Adrian Raudaschl, who has spearheaded Scopus AI at Elsevier, said at a recent IPPO event: “Your star is your query”. His team are testing how to apply generative AI to Scopus, the publisher’s abstract and citation database of peer-reviewed literature in order to help researchers get deeper insights faster, and expect to roll-out the full product in 2024. As with ChatGPT individuals will need to become familiar with how to use prompts effectively, and seek out training to help use prompts appropriately, and enable them to think beyond their limitations.
Elsevier has also been developing new ways to support policymakers who rely on readily available synopses of ‘good evidence’ during times of decision-making. The production of such synthetic work has traditionally been very time-intensive, and often arrives too late to be of use, particularly in a crisis. A team lead by Boaz Kwakkel, now an associate systems engineer at Cisco, worked with Elsevier to test how conversational large language models could be used to generate policy briefs based on scientific evidence
His team asked their tool to write a policy brief on Lithium Development, and were surprised by the quality of the result. In a survey of 30 people from policy organisations around the world, the consensus was that it was not obvious that this brief was machine generated, even after several readings. The tool could have been very useful during the pandemic, if for example politicians needed the best evidence in real time, covering not just predicted infection rates, but wider social impacts such as on inequality, education and mental health. However its level of scientific quality fell below what the Elsevier team would have expected given the wealth of literature fed into the model. Elsevier’s projects are impressive. But a big issue for the future will be how much tools can rely on proprietary databases and how much they can rely on open access data.
Judging Whether the Best Evidence is Being Used
We’ve also been looking at new tools to judge whether policy-makers are using the best or most relevant evidence to guide them. Here a range of new tools are possible that were simply not available even 2-3 years ago.
With the increased availability of open access research and increased computing power, we are now also in a position to see where the supply of knowledge is coming from, who is creating it, how they are bringing it into use, and whether we are valuing all knowledge equally. We can also see where the sparks of innovation are coming from. All highly valuable tools for better understanding how we can make the most of our global research.
The work of STEaPP’s Basil Mahfouz is showing how to combine detailed analysis of policy documents – using Overton’s database of millions of white papers and reports from around the world – with detailed analysis of the research supply.
This makes it possible to assess whether countries – and policy makers – are using the best, most relevant and most uptodate research. His work has focused on education policy through the pandemic and most recently on the IPCC’s work on climate change.
These tools are still novel – but in time could become part of the everyday toolkit, providing prompts to policy makers if the diagnosis shows distortions in terms of what evidence they are using. Again, they still need expert humans to judge their messages – but in time they may greatly improve the speed and quality of evidence synthesis processes.
Embedding Evidence in Daily Decision Making
Finally, we’re interested in how you can embed evidence into the everyday life of governments. Here it’s not enough to use the various tools described earlier, though these help. Ideally you link these to policies that are already being developed or implemented and use them to assess whether you hope for impact and theories of change. The REX (Results and Evidence eXchange) project, developed by Tom Wilkinson for the Foreign, Commonwealth & Development Office (FCDO) shows how this could be done.
The team wanted to harness the knowledge held by people delivering projects on the frontline that isn’t captured by traditional metrics, while also bringing in both evidence and data on impacts. According to Tom Wilkinson, who is now Chief Data Officer in the Scottish Government, the aim of REX was to give people working in different areas, in seemingly different ways, a common language through which to talk about what results had been delivered and why. This would then allow data analysts to map how teams developed and delivered their interventions, which in turn could be served up in a combined form [see image below].
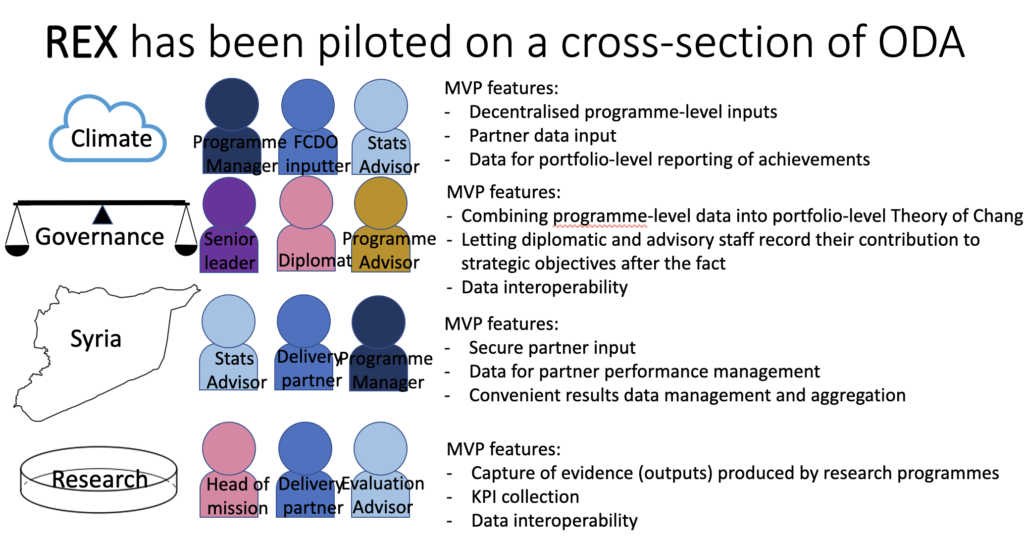
This image demonstrates how REX has been used to summarise the activities of a range of Official Development Assistance (ODA) projects.
A key aim was to show common causal thinking across a collection of disparate activities. From there, REX data analysts developed a software platform that could create causal networks based on these individual activities. For example, to demonstrate that treating infectious diseases leads to greater government support for public health care, which will in turn lead to improved access to health services.
Next Steps
Our conclusion is that variants of these tools will fairly quickly become mainstream. They need to combine with intelligent human judgement rather than being an alternative to it.
But they will greatly speed the job of synthesis and will often be able to produce good enough summaries in close to real time. We will keep tracking these tools since they are so relevant to IPPO’s work and will publish another overview in a few months time.
Further Reading/Resources
Are you looking for health evidence? Try here
Quick, but not dirty – Can rapid evidence reviews reliably inform policy?
Time for Sensemaking 3.0? The potential of AI-powered portfolio analytics to drive impact